Paola Cascante-Bonilla
Assistant Professor. Department of Computer Science. Stony Brook University (SUNY).
Paola Cascante-Bonilla is a tenure-track Assistant Professor in the Department of Computer Science at Stony Brook University (SUNY). Before that, she was a Postdoctoral Associate at the University of Maryland Institute for Advanced Computer Studies (UMIACS), working with Professor Hal Daumé III, developing methods and metrics related to trustworthy machine learning. She received her Ph.D. in Computer Science at Rice University in 2024, advised by Professor Vicente Ordóñez Román, working on Computer Vision, Natural Language Processing, and Machine Learning. She is the recipient of the Ken Kennedy Institute SLB Graduate Fellowship (2022/23), and was selected as a Future Faculty Fellow by Rice's George R. Brown School of Engineering (2023) and as a Rising Star in EECS (2023). She received a Master of Computer Science at the University of Virginia and a B.S. in Engineering at the Tecnológico de Costa Rica. Previously, she interned at the Mitsubishi Electric Research Laboratories (MERL) and twice at the MIT-IBM Watson AI Lab. Before that, she spent 10 years working as a Software Engineer at different tech companies -- CV.

dialpad Vision and Language & Multi-modal learning:Zero/few-shot learning, representation learning, continual learning.
Visual-question answering, crossmodal retrieval, multi-hop reasoning.
directions_run Synthetic data generation for compositionality and privacy protection:Simulated environments to provide a safe, controlled setting where agents can learn.
Virtual playgrounds that allow systems to experience and interact within the 3D space.
high_quality Dynamic evaluations and real-world applications:Data distribution and mitigation of spurious correlations.
Assessing the performance and effectiveness of models under varying conditions.
> Area Chair for ECCV 2026, CVPR 2025-2026, COLM 2025-2026, BMVC 2025-2026.
> Co-organizing the Machine Learning Summer School (2026) in New York City, at the Columbia University campus.
07/2026. Enhancing Vision Language Models' Robustness Under Adverse Imaging Conditions is accepted to #COLM2026🐐
05/2026. Our egocentric perception research is supported by the Vetto AI & Latinx in AI (LXAI) Research Program~! 🌱
04/2026. Keynote at NYC Computer Vision Day.
03/2026. Our egocentric perception research is supported by the
02/2026. Invited talk at Rice University: Transitioning to a Faculty Position: Insights from a Former Fellow.
08/2025. Invited talk at University of Costa Rica (Archival Studies Section of the School of History / virtual).
07/2025. Learning from Synthetic Data for Visual Grounding is accepted to #BMVC2025!
07/2025. Beyond Blanket Masking is accepted to #COLM2025!
05/2025. VL Alignment via Hallucination Correction is accepted to #ACL2025 (Findings)!
04/2025. Guest Lecture at the University of Pittsburgh: Unlocking Compositional Reasoning in Vision-Language Models.
01/2025. CECE is accepted to #ICLR2025!
09/2024. One paper accepted to #EMNLP2024 (Findings)!
07/2024. One paper accepted to #ECCV2024!
07/2024. Started a postdoc with Hal Daumé III at UMD!
05/2024. Pleased to be recognized as an Outstanding Reviewer for #CVPR2024!
02/2024. One paper accepted to #CVPR2024!
02/2024. I was invited to give a talk at the AI Safety research club @ UCLA.
12/2023. Our second edition of "What is Next in Multimodal Foundation Models? - MMFM Workshop" is accepted to #CVPR2024. See you in Seattle! ✨
09/2023. One paper accepted to #NeurIPS2023 as spotlight! Quite fun to work with LLMs for Vision+Language~!
08/2023. I've been selected to Rising Stars in EECS (2023) to be held in Georgia Tech, Atlanta!
08/2023. I've been accepted to the #ICCV2023 Doctoral Consortium & granted an award for attending ICCV!
07/2023. I've been selected as a Future Faculty Fellow for the 2023-2024 academic year! 📢
07/2023. Going beyond nouns... is accepted to #ICCV2023! - Work featured in MIT News and Rice CS News.
05/2023. Pleased to be recognized as an Outstanding Reviewer for #CVPR2023!
03/2023. I'm co-organizing the Women in Computer Vision (WiCV) and What is Next in Multimodal Foundation Models? (MMFM) workshops at #ICCV2023! See you in Paris!
03/2023. I accepted a Research PhD Internship at MERL this Summer to work on Few-shot Action Recognition!
02/2023. Two papers accepted to #CVPR2023 on lifelong/continual learning! update
01/2023. I got awarded the Ken Kennedy Institute 2022/23 SLB Graduate Fellowship.
03/2022. SimVQA is accepted to #CVPR2022. Work featured in Rice News.
01/2022. Co-organizing the LatinXinCV research workshop at CVPR 2022. Co-chairing the Mentorship Program.
01/2022. I'm moving to Houston, TX to continue my PhD at Rice University.
12/2021. I'm returning to the MIT-IBM Watson AI Lab as a PhD Intern Researcher next Summer. [
 ]
]11/2021. One paper accepted to BMVC 2021. It's all about image patches grid_on and evolution! sync_problem
09/2021. Got my Master's in Computer Science at the University of Virginia. GPA 4.0.
05/2021. Featured as the talent of May in the Costa Rican Talent Network Abroad (Ticotal). National Science Academy, Costa Rica.
01-10/2021. Co-organizing the LatinXinCV research workshop at CVPR 2021, ICML 2021, ICCV 2021. Co-chairing the Mentorship Program.
02/2021. Curriculum Labeling got accepted to AAAI 2021.
01/2021. Accepted a Summer PhD Internship at the MIT-IBM Watson AI Lab. [
]08/2020. Invited to give a workshop at the International Meeting on Artificial Intelligence and its Applications (RIIAA).



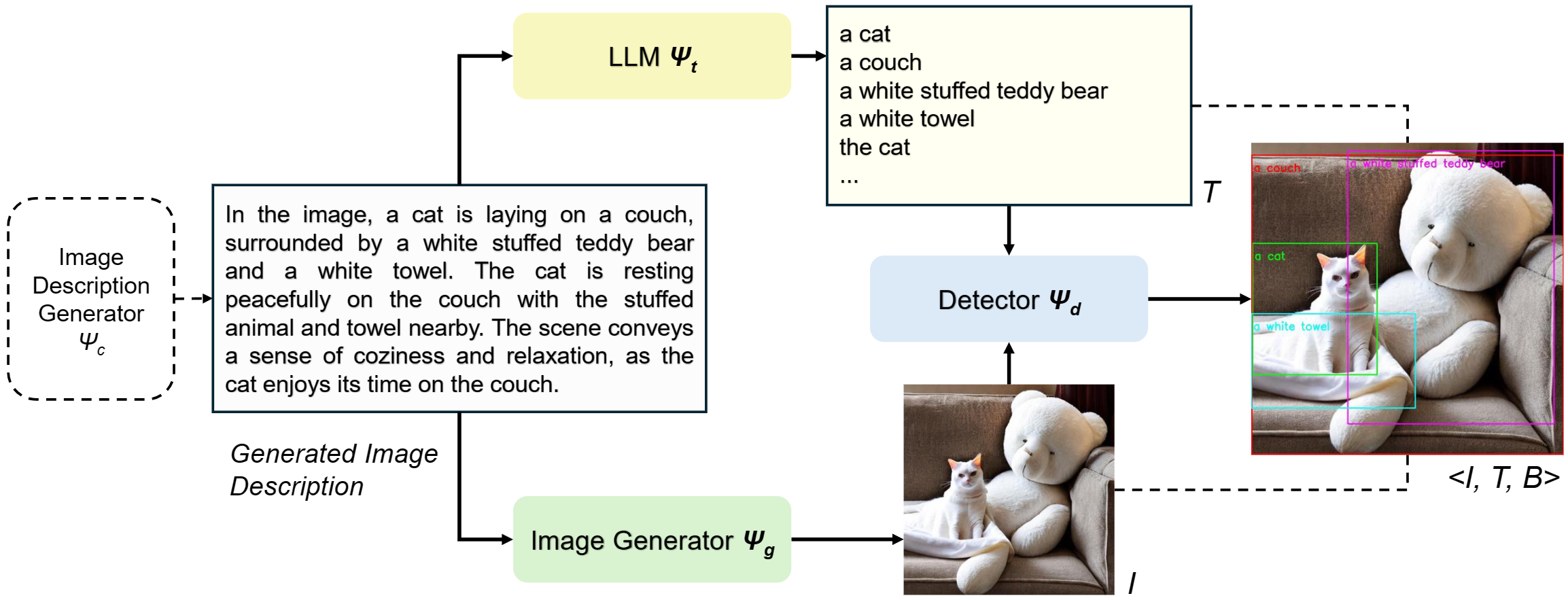 |
Learning from Synthetic Data for Visual Grounding.
Ruozhen He, Ziyan Yang, Paola Cascante-Bonilla, Alexander C. Berg, Vicente Ordóñez. The British Machine Vision Conference. BMVC 2025. Sheffield, UK. November 2025. [webpage] | |
| Beyond Blanket Masking: Examining Granularity for Privacy Protection in Images Captured by Blind and Low Vision Users.
Jeffri Murrugarra-Llerena, Haoran Niu, Suzanne Barber, Hal Daumé III, Yang Trista Cao, Paola Cascante-Bonilla. Second Conference on Language Modeling. COLM 2025. Montreal, Canada. October 2025. • Short version presented at the VizWiz Workshop and LXAI Workshop at CVPR 2025. [bibtex] [webpage] [code] | ||
 |
Can Hallucination Correction Improve Video-Language Alignment?.
Lingjun Zhao, Mingyang Xie, Paola Cascante-Bonilla, Hal Daumé III, Kwonjoon Lee. The 63rd Annual Meeting of the Association for Computational Linguistics. ACL Findings 2025. Vienna, Austria. July 2025. [bibtex] | |
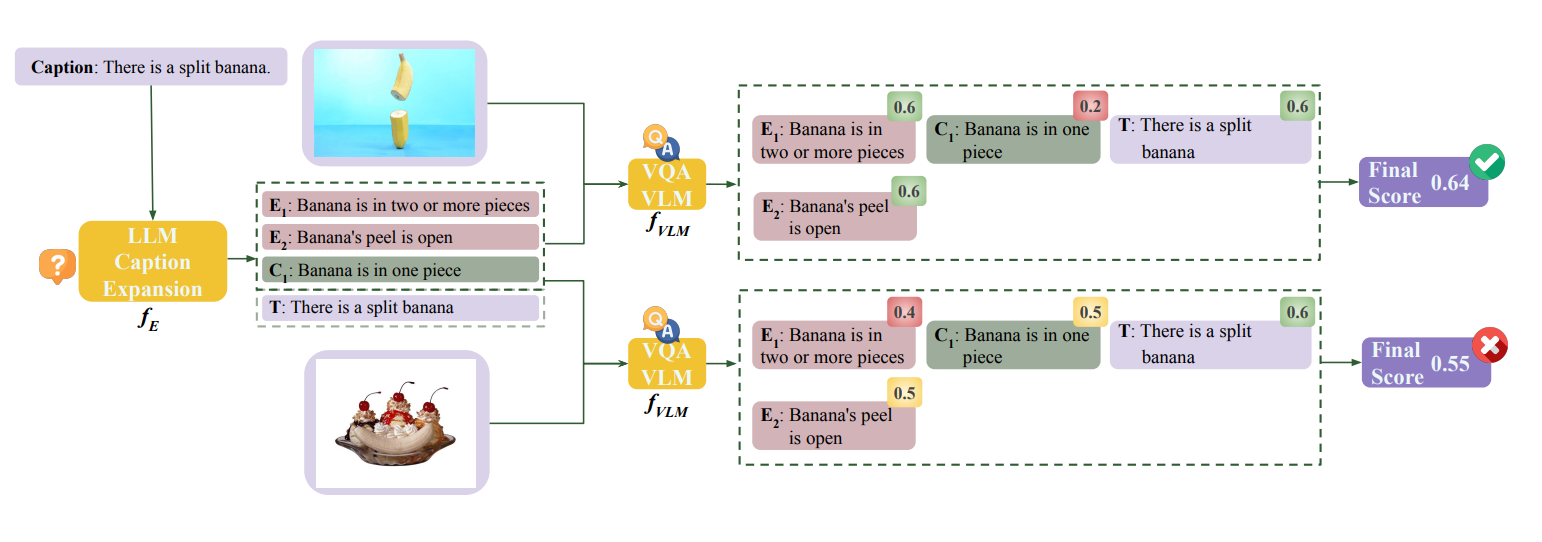 |
Natural Language Inference Improves Compositionality in Vision-Language Models.
Paola Cascante-Bonilla, Yu Hou, Yang Trista Cao, Hal Daumé III, Rachel Rudinger. The Thirteenth International Conference on Learning Representations. ICLR 2025. Singapore. April 2025. [project page] [bibtex] | |
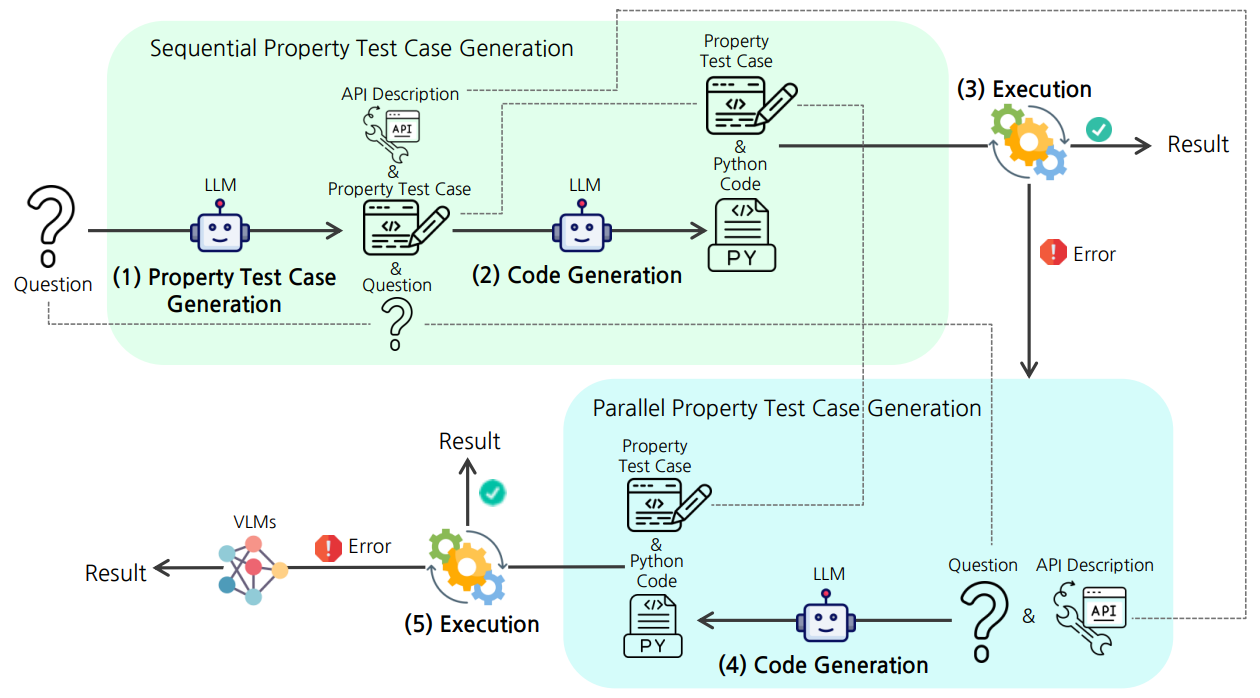 |
PropTest: Automatic Property Testing for Improved Visual Programming. Jaywon Koo, Ziyan Yang, Paola Cascante-Bonilla, Baishakhi Ray, Vicente Ordóñez. Findings of Empirical Methods in Natural Language Processing. EMNLP Findings 2024. Miami, Florida. November 2024. [project page] [bibtex] | |
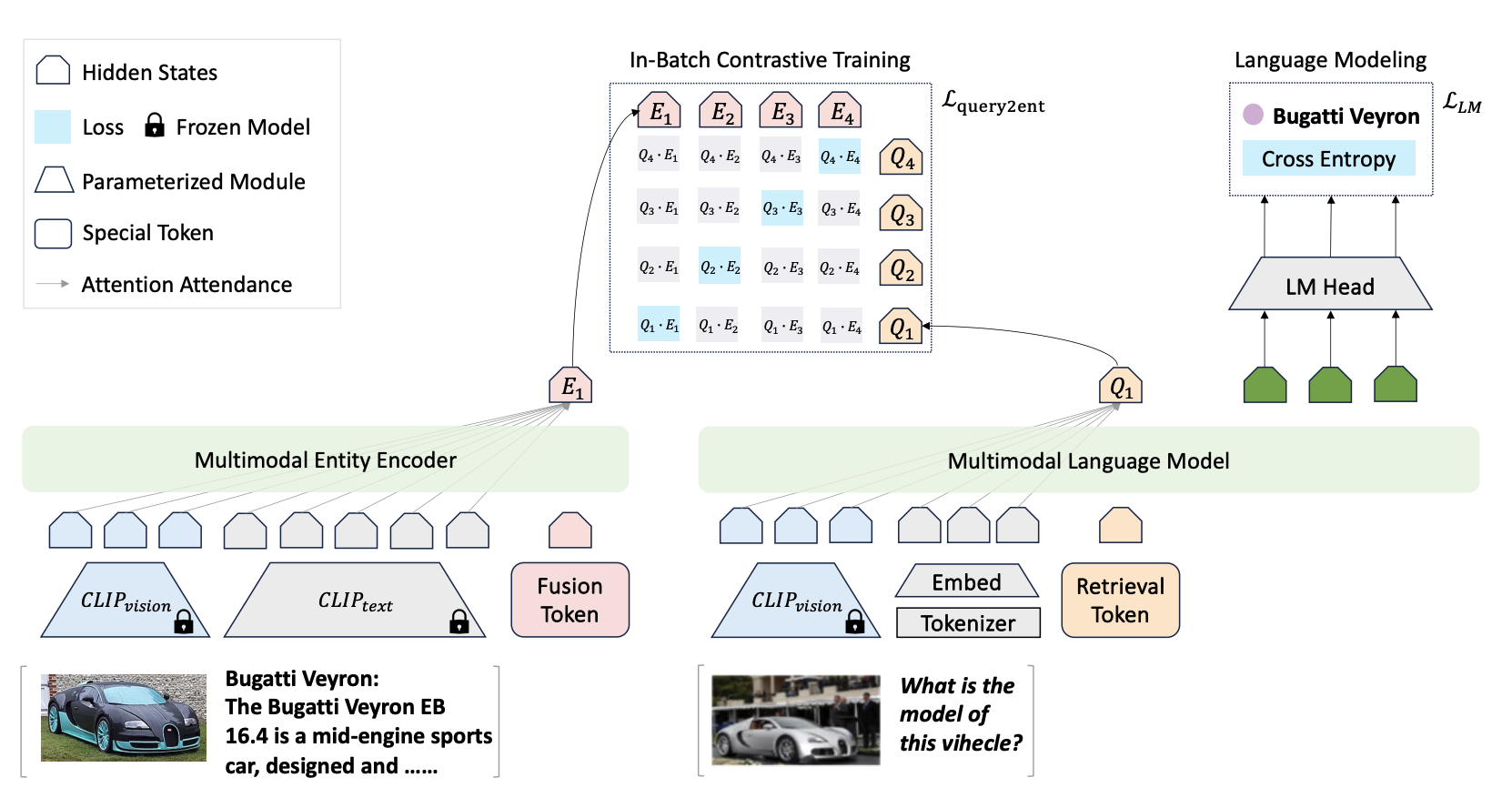 |
Grounding Language Models for Visual Entity Recognition. Zilin Xiao, Ming Gong, Paola Cascante-Bonilla, Xingyao Zhang, Jie Wu, and Vicente Ordonez. 2024 European Conference on Computer Vision. ECCV 2024. Milano, Italy. September 2024. [code] [bibtex] | |
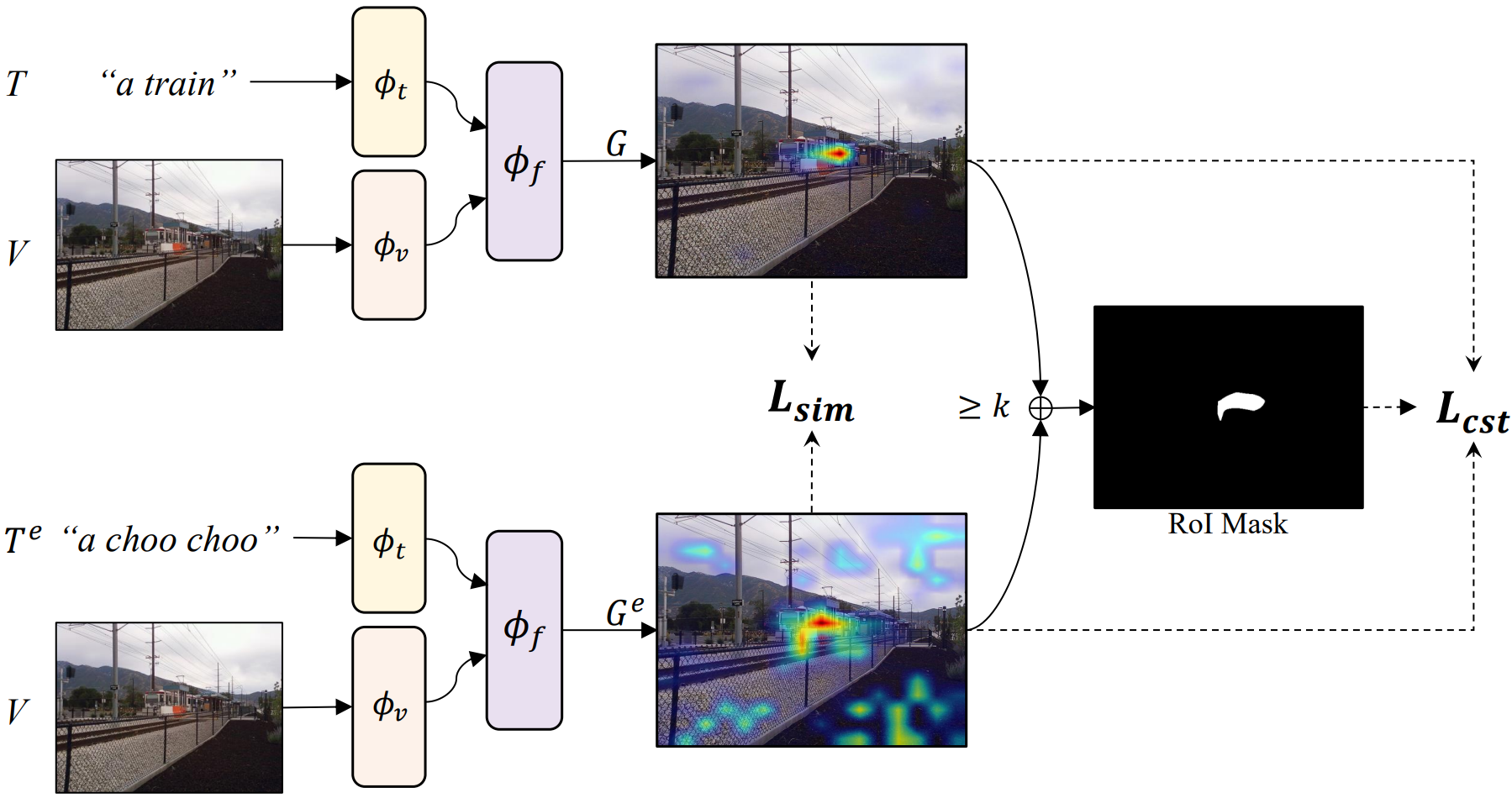 |
Improved Visual Grounding through Self-Consistent Explanations. Ruozhen He, Paola Cascante-Bonilla, Ziyan Yang, Alexander C. Berg, Vicente Ordóñez. 2024 Conference on Computer Vision and Pattern Recognition. CVPR 2024. Seattle, Washington. June 2024. [project page] [bibtex] | |
 |
Dense and Aligned Captions (DAC) Promote Compositional Reasoning in VL Models (spotlight). Sivan Doveh, Assaf Arbelle, Sivan Harary, Roei Herzig, Donghyun Kim, Paola Cascante-Bonilla, Amit Alfassy, Rameswar Panda, Raja Giryes, Rogerio Feris, Shimon Ullman, Leonid Karlinsky. Thirty-seventh Conference on Neural Information Processing Systems. NeurIPS 2023. New Orleans, Lousiana. December 2023. [arxiv] [bibtex] | |
 |
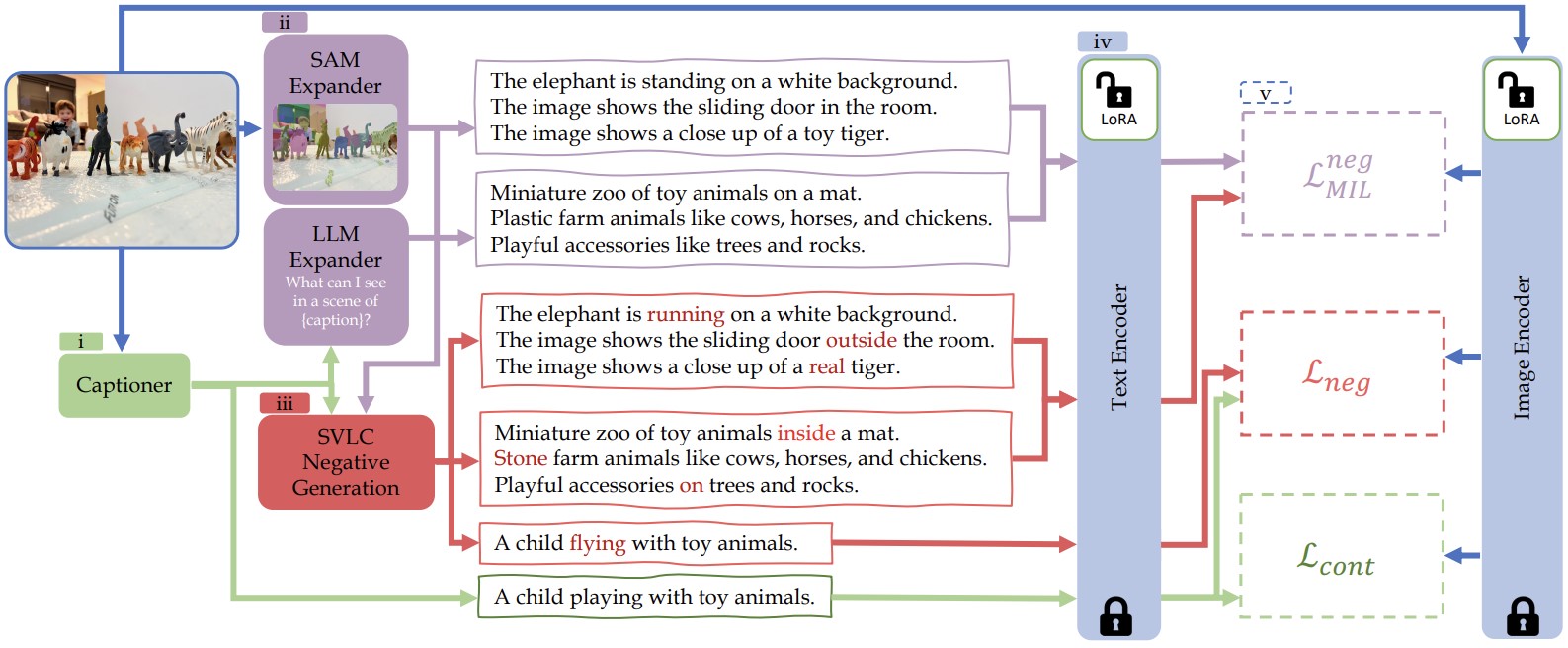
Going Beyond Nouns With Vision & Language Models Using Synthetic Data. Paola Cascante-Bonilla, Khaled Shehada, James Seale Smith, Sivan Doveh, Donghyun Kim, Rameswar Panda, Gül Varol, Aude Oliva, Vicente Ordonez, Rogerio Feris, Leonid Karlinsky. The 19th International Conference on Computer Vision. ICCV 2023. Paris, France. December 2023. [arxiv] [project page] [bibtex] | |
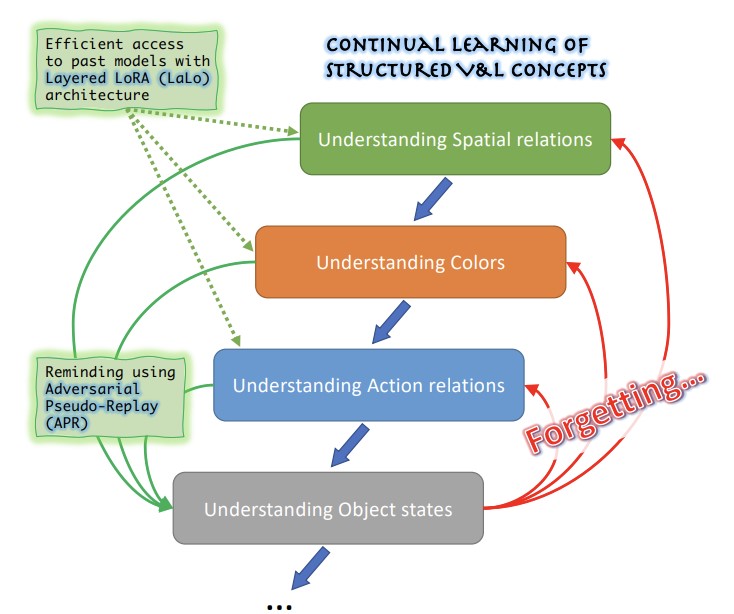 |
ConStruct-VL: Data-Free Continual Structured VL Concepts Learning. James Seale Smith, Paola Cascante-Bonilla, Assaf Arbelle, Donghyun Kim, Rameswar Panda, David Cox, Diyi Yang, Zsolt Kira, Rogerio Feris, Leonid Karlinsky. 2023 Conference on Computer Vision and Pattern Recognition. CVPR 2023. Vancouver, Canada. June 2023. [arxiv] [bibtex] | |
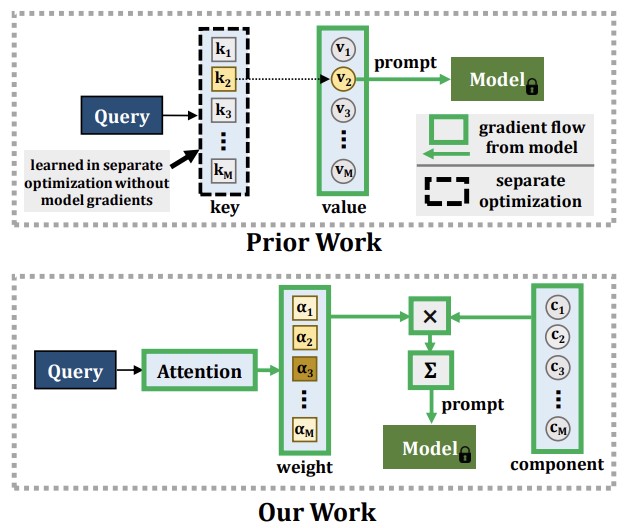 |
CODA-Prompt: COntinual Decomposed Attention-based Prompting for Rehearsal-Free Continual Learning. James Seale Smith, Leonid Karlinsky, Vyshnavi Gutta, Paola Cascante-Bonilla, Donghyun Kim, Assaf Arbelle, Rameswar Panda, Rogerio Feris, Zsolt Kira. 2023 Conference on Computer Vision and Pattern Recognition. CVPR 2023. Vancouver, Canada. June 2023. [arxiv] [bibtex] | |
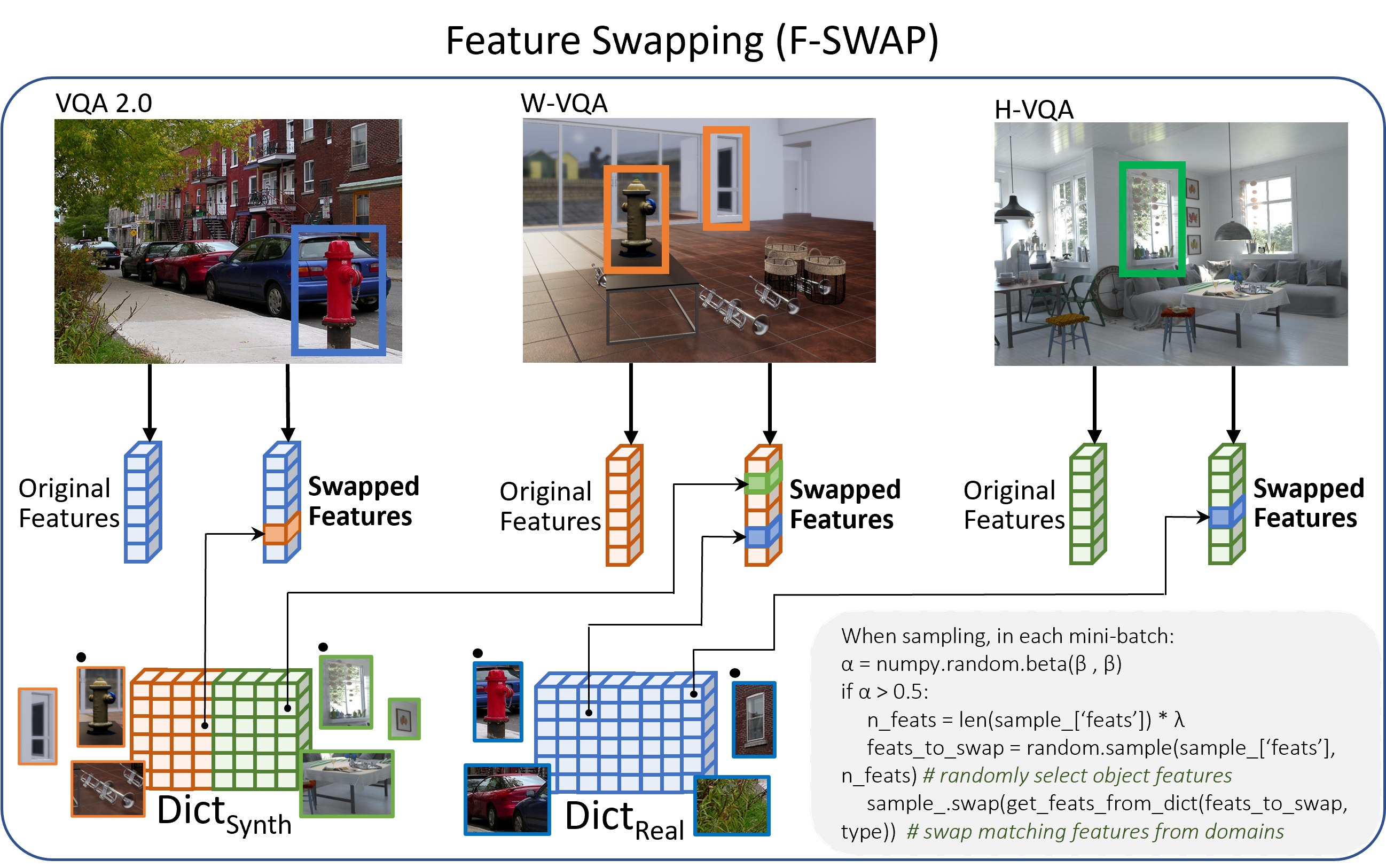 |
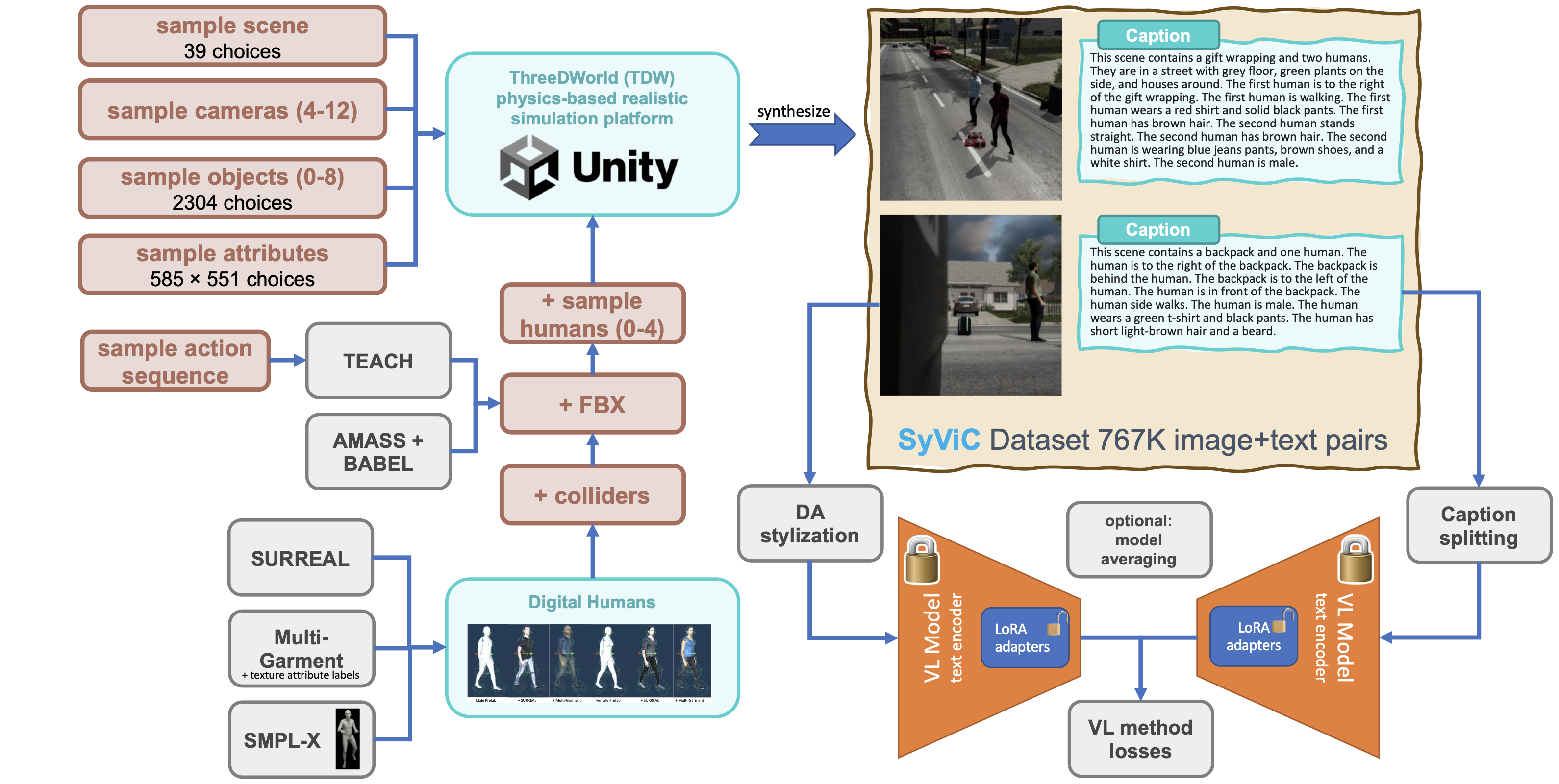
SimVQA: Exploring Simulated Environments for Visual Question Answering. Paola Cascante-Bonilla, Hui Wu, Letao Wang, Rogerio Feris, Vicente Ordonez. 2022 Conference on Computer Vision and Pattern Recognition. CVPR 2022. New Orleans, Lousiana. June 2022. [arxiv] [project page] [bibtex] |
|
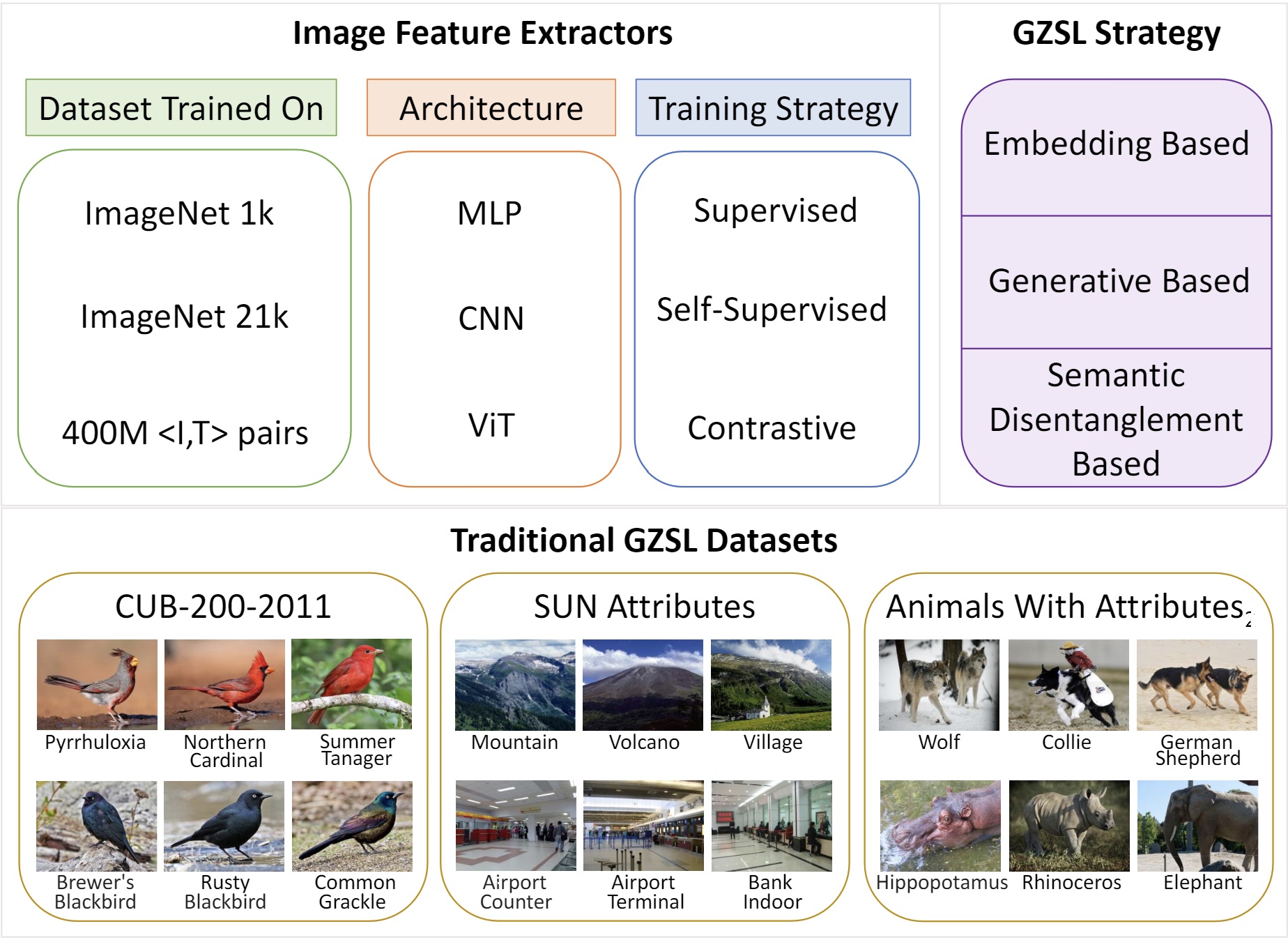 |
On the Transferability of Visual Features in Generalized Zero-Shot Learning. Paola Cascante-Bonilla, Leonid Karlinsky, James Seale Smith, Yanjun Qi, Vicente Ordóñez. November 2022. [code] [bibtex] | |
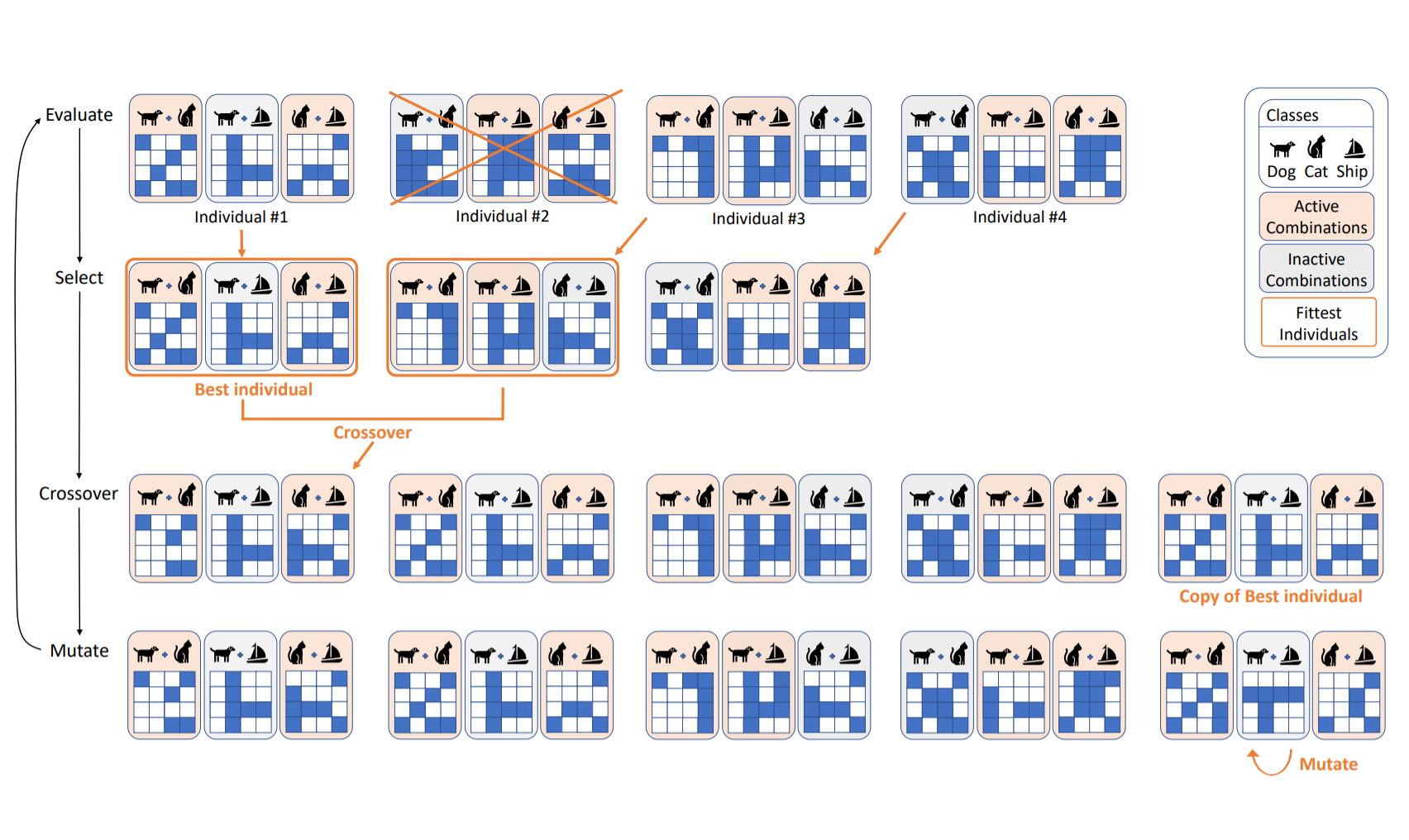 |
Evolving Image Compositions for Feature Representation Learning. Paola Cascante-Bonilla, Arshdeep Sekhon, Yanjun Qi, Vicente Ordonez. The 32nd British Machine Vision Conference. BMVC 2021. Virtual Conference. November 2021. [arxiv] [project page] [bibtex] |
|
 |
Curriculum Labeling: Revisiting Pseudo-Labeling for Semi-Supervised Learning. Paola Cascante-Bonilla, Fuwen Tan, Yanjun Qi, Vicente Ordonez. The 35th AAAI Conference on Artificial Intelligence. AAAI 2021. Virtual Conference. February 2021. [arxiv] [code] [bibtex] |
|
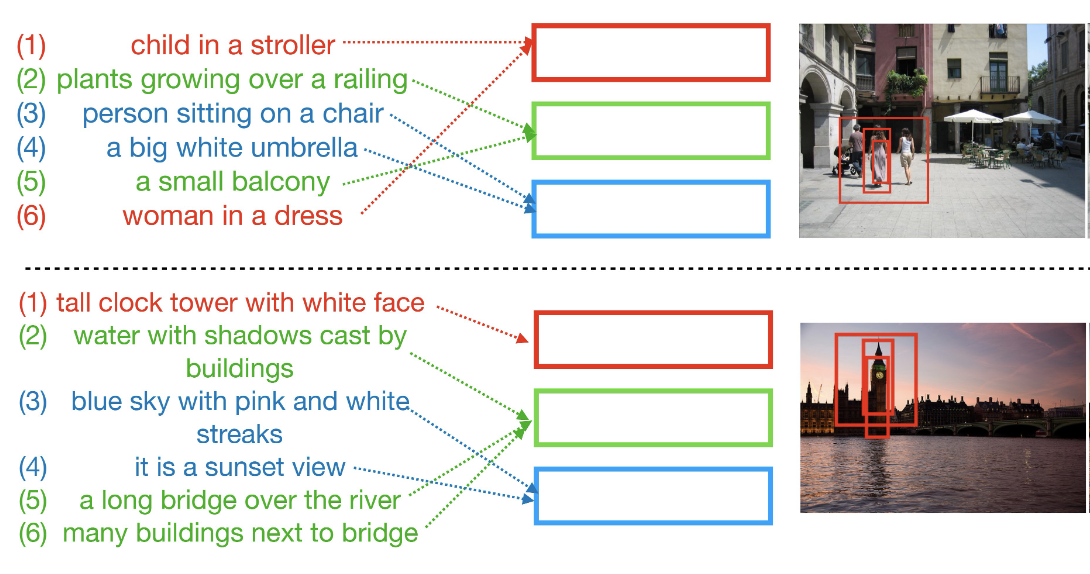 |
Drill-down: Interactive Retrieval of Complex Scenes using Natural Language Queries. Fuwen Tan, Paola Cascante-Bonilla, Xiaoxiao Guo, Hui Wu, Song Feng, Vicente Ordonez. Conf. on Neural Information Processing Systems. NeurIPS 2019. Vancouver, Canada. December 2019. [arxiv] [code] [bibtex] |
|
 |
Moviescope: Large-scale Analysis of Movies using Multiple Modalities. Paola Cascante-Bonilla, Kalpathy Sitaraman, Mengjia Luo, Vicente Ordonez. August 2019. [arxiv] [project page] [bibtex] Media coverage: techxplore article |
|
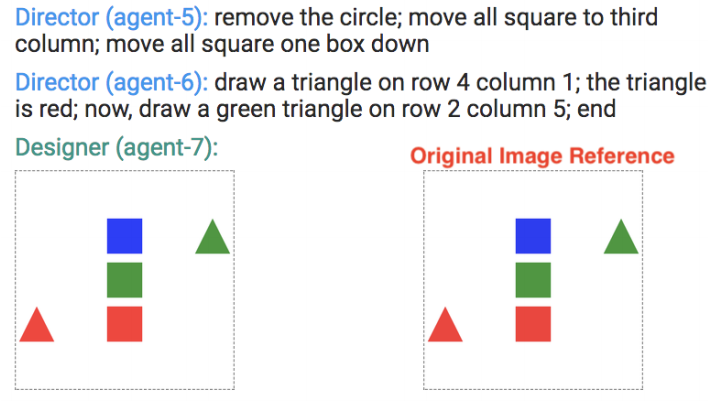 |
Chat-crowd: A Dialog-based Platform for Visual Layout Composition. Paola Cascante-Bonilla, Xuwang Yin, Vicente Ordonez, Song Feng. North American Chapter of the Association for Computational Linguistics. NAACL 2019. System Demonstrations. Minneapolis, Minnesota. June 2019. [arxiv] [project page] [code] [bibtex] |

Postdoctoral Associate.
Supervisor: Hal Daumé III.
July 2024 - July 2025.

Research Intern in the Computer Vision Group. Working in Few-shot Action Recognition.
Host: Anoop Cherian.
May 2023 - August 2023.

Research Intern in the Vision Group at the MIT-IBM Watson AI Lab.
Mentor: Leonid Karlinsky. Manager: Rogerio Feris.
May 2022 - March 2023.
Research Intern in the Vision Group at the MIT-IBM Watson AI Lab.
Exploring simulated environments for Visual Question Answering.
Mentor: Hui Wu. Manager: Rogerio Feris.
May 2021 - Aug 2021.



Area Chair: CVPR 2025, COLM 2025, BMVC 2025.
Reviewer: CVPR 2022-2024, ECCV 2022-2024, ICCV 2023, WACV 2024-2025, NeurIPS 2022-2024, AAAI 2022-2025, ICLR 2024-2025, ICML 2024, WACV 2024-2025, BMVC 2021, ACMMM 2022 Industry Track.
Co-organizer for the What is Next in Multimodal Foundation Models? - MMFM Workshop @ ICCV2023 & CVPR2024.
Co-organizing the LatinX in CV Workshop @ CVPR2021, ICCV 2021, ICML 2021, CVPR2022. Co-chairing the Mentorship Program.
2002 - 2016.